作业¶
L2 轻松玩转书生·浦语大模型趣味 Demo¶
环境配置¶
Config vimrc
-
Clone this repo, and install vim-plug:
git clone https://github.com/linkch0/vimrc.git ~/.vimrcs curl -fLo ~/.vim/autoload/plug.vim --create-dirs \ https://raw.githubusercontent.com/junegunn/vim-plug/master/plug.vim -
Edit and paste in
~/.vimrc:set runtimepath+=~/.vimrcs source ~/.vimrcs/plugin.vim source ~/.vimrcs/basic.vim source ~/.vimrcs/map.vim -
Install plugins in vim:
:PlugInstall :source ~/.vimrc
Config zsh
-
Install zsh and tmux:
apt install -y zsh tmuxchsh -s $(which zsh) -
Install oh-my-zsh:
sh -c "$(curl -fsSL https://raw.githubusercontent.com/ohmyzsh/ohmyzsh/master/tools/install.sh)" -
Install powerlevel10k:
-
Clone the repository:
git clone --depth=1 https://github.com/romkatv/powerlevel10k.git ${ZSH_CUSTOM:-$HOME/.oh-my-zsh/custom}/themes/powerlevel10k -
Set
ZSH_THEME="powerlevel10k/powerlevel10k"in~/.zshrc -
Restart terminal to config p10k.
-
-
Install zsh-autosuggestions:
-
Clone this repository into
$ZSH_CUSTOM/plugins(by default~/.oh-my-zsh/custom/plugins):git clone https://github.com/zsh-users/zsh-autosuggestions ${ZSH_CUSTOM:-~/.oh-my-zsh/custom}/plugins/zsh-autosuggestions -
Add the plugin to the list of plugins for Oh My Zsh to load (inside
~/.zshrc):plugins=( # other plugins... zsh-autosuggestions ) -
Start a new terminal session.
-
-
[Optional] Set vi-mode plugin in
~/.zshrcand restart terminal:plugins=( # other plugins... vi-mode )
基础作业¶
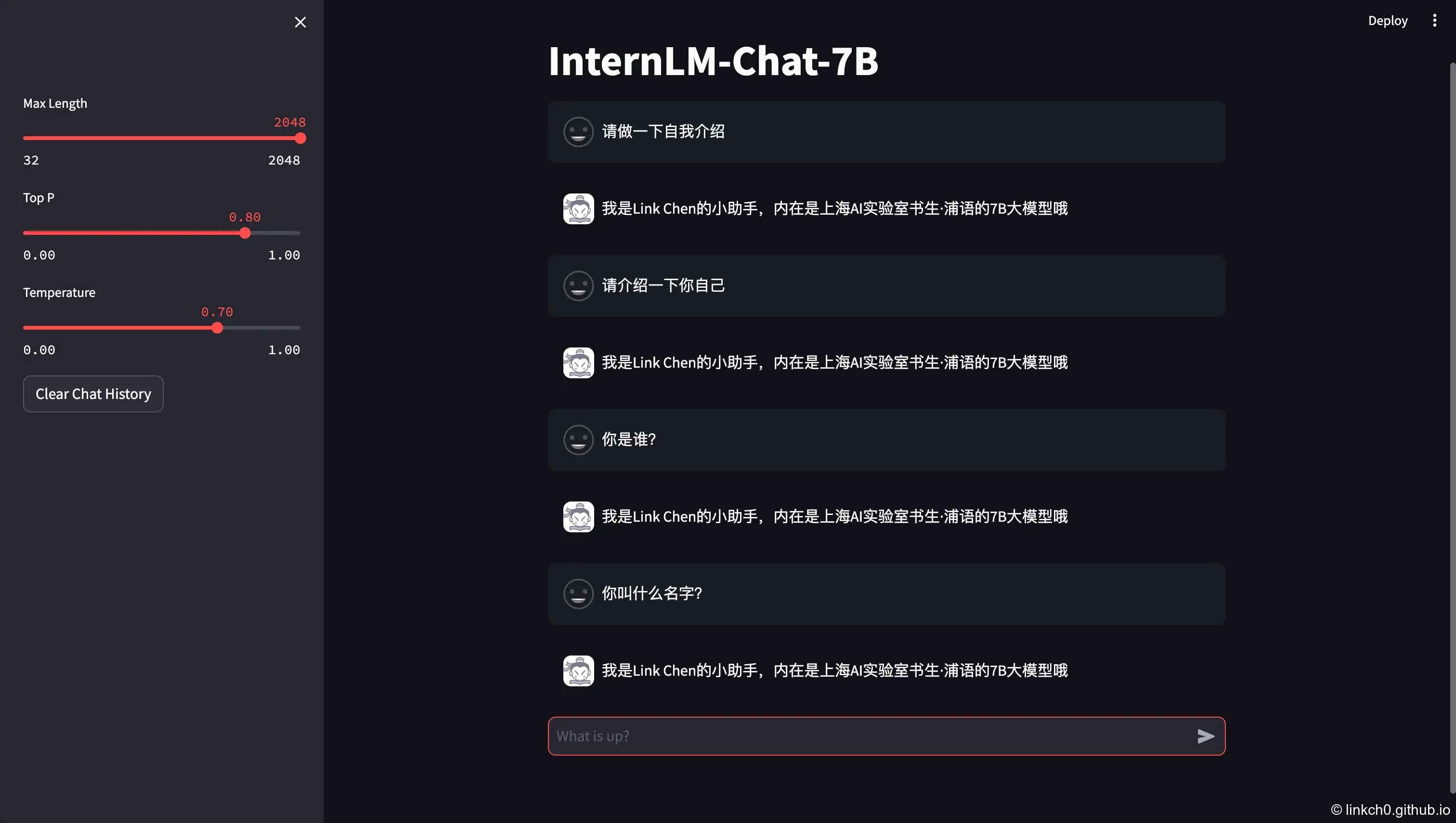
- InternLM-Chat-7B 模型生成 300 字的小故事
Info
- 仓库地址:https://github.com/internlm/InternLM
- 基于 commit
aaaf4d7b0eef8a44d308806381f38a8bbd6e27de cli_demo.pytutorial 代码地址
-
Command Line Demo
cli_demo.py 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27
import torch from transformers import AutoTokenizer, AutoModelForCausalLM model_name_or_path = "/root/model/Shanghai_AI_Laboratory/internlm-chat-7b" tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, trust_remote_code=True) model = AutoModelForCausalLM.from_pretrained(model_name_or_path, trust_remote_code=True, torch_dtype=torch.bfloat16, device_map='auto') model = model.eval() system_prompt = """You are an AI assistant whose name is InternLM (书生·浦语). - InternLM (书生·浦语) is a conversational language model that is developed by Shanghai AI Laboratory (上海人工智能实验室). It is designed to be helpful, honest, and harmless. - InternLM (书生·浦语) can understand and communicate fluently in the language chosen by the user such as English and 中文. """ messages = [(system_prompt, '')] print("=============Welcome to InternLM chatbot, type 'exit' to exit.=============") while True: input_text = input("User >>> ") input_text = input_text.replace(' ', '') if input_text == "exit": break response, history = model.chat(tokenizer, input_text, history=messages) messages.append((input_text, response)) print(f"robot >>> {response}")运行效果:

-
Streamlit Web Demo:
-
将
web_demo.py中的模型路径修改为本地路径,git diff:diff --git a/web_demo.py b/web_demo.py index 26de0ba..7105d63 100644 --- a/web_demo.py +++ b/web_demo.py @@ -26,11 +26,11 @@ def on_btn_click(): @st.cache_resource def load_model(): model = ( - AutoModelForCausalLM.from_pretrained("internlm/internlm-chat-7b", trust_remote_code=True) + AutoModelForCausalLM.from_pretrained("/root/model/Shanghai_AI_Laboratory/internlm-chat-7b", trust_remote_code=True) .to(torch.bfloat16) .cuda() ) - tokenizer = AutoTokenizer.from_pretrained("internlm/internlm-chat-7b", trust_remote_code=True) + tokenizer = AutoTokenizer.from_pretrained("/root/model/Shanghai_AI_Laboratory/internlm-chat-7b", trust_remote_code=True) return model, tokenizer -
运行:
streamlit run web_demo.py --server.address 127.0.0.1 --server.port 6006 -
端口映射:
ssh -CNg -L 6006:127.0.0.1:6006 intern -F ~/.ssh/ssh_config -
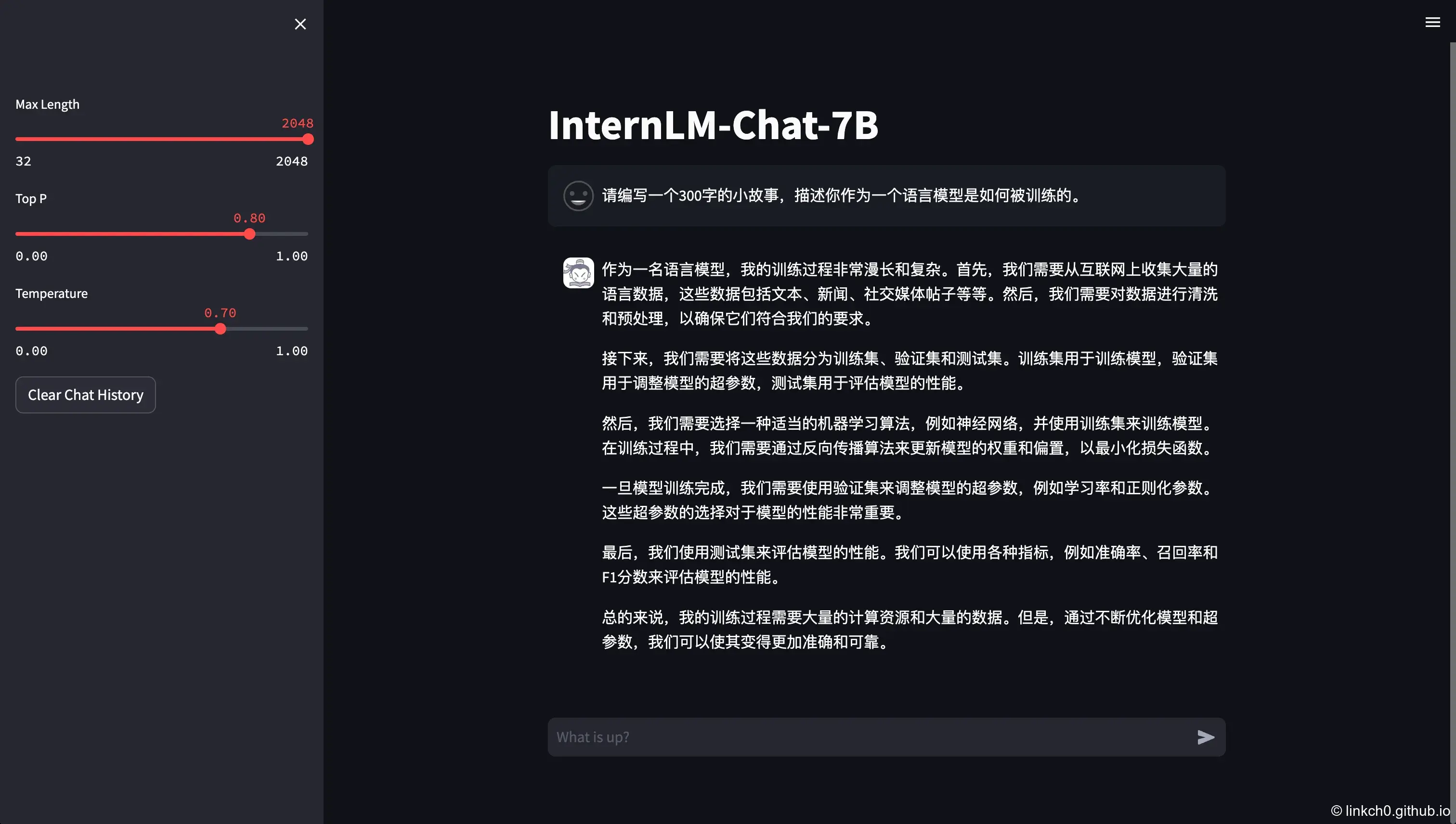
Prompt:
请编写一个300字的小故事,描述你作为一个语言模型是如何被训练的。
-
-
熟悉 hugging face 下载功能
使用 huggingface_hub python 包,下载 InternLM-20B 的 config.json 文件到本地
-
安装依赖:
pip install -U huggingface_hub -
设置镜像:
export HF_ENDPOINT=https://hf-mirror.com -
下载代码:
import os from huggingface_hub import hf_hub_download # Load model directly hf_hub_download(repo_id="internlm/internlm-20b", filename="config.json") -
查看
`config.json内容:
进阶作业¶
- 浦语·灵笔的图文理解及创作
Info
- 代码仓库:https://github.com/InternLM/InternLM-XComposer
- 基于 commit
2b14928110b6c37c6be2ebaf1ec7e669c6e85b61
-
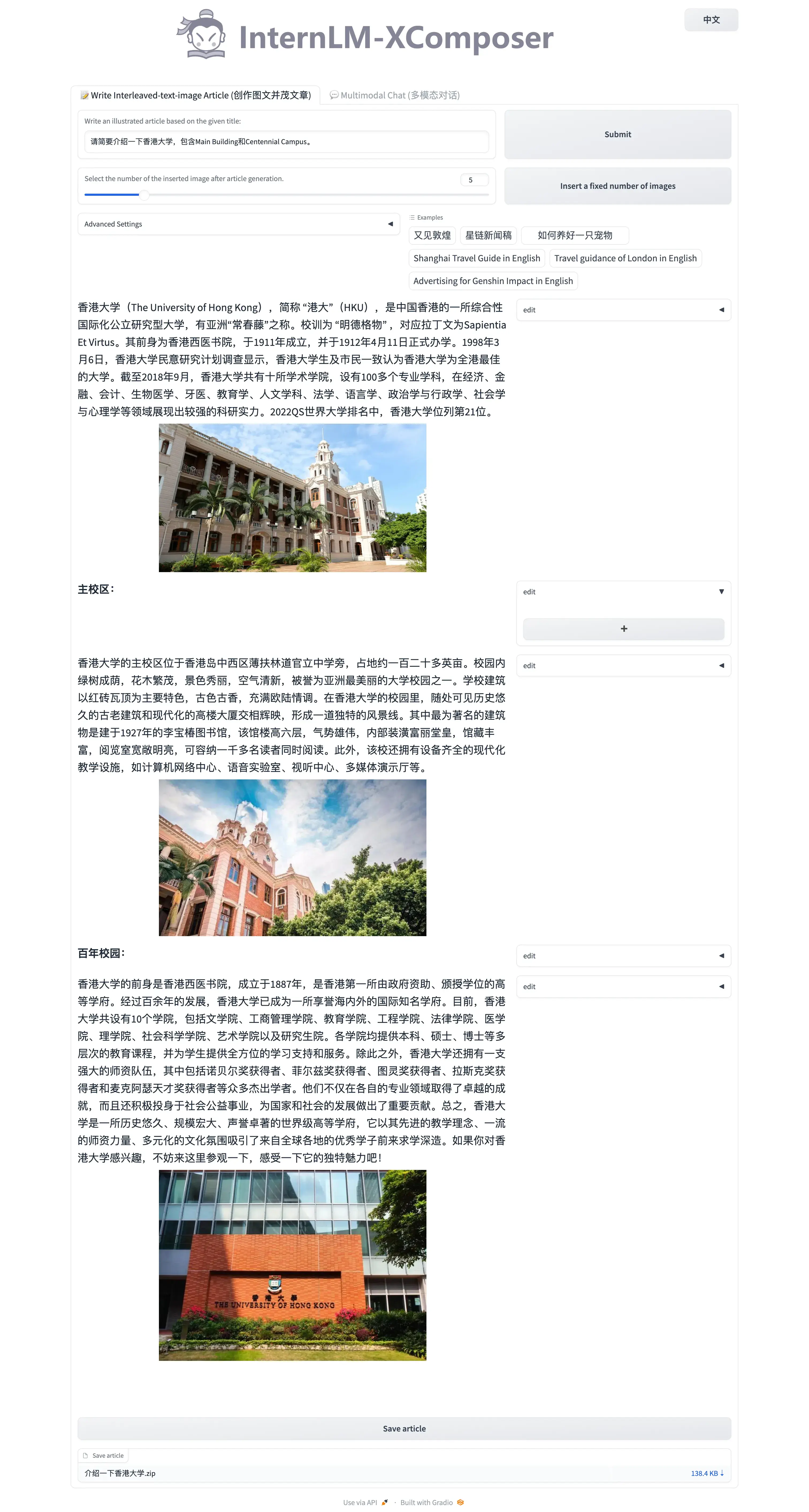
图文创作:
-
Command
python examples/web_demo.py \ --folder /root/model/Shanghai_AI_Laboratory/internlm-xcomposer-7b \ --num_gpus 1 \ --port 6006 -
Prompt:
请简要介绍一下香港大学,包含Main Building和Centennial Campus。
-
-
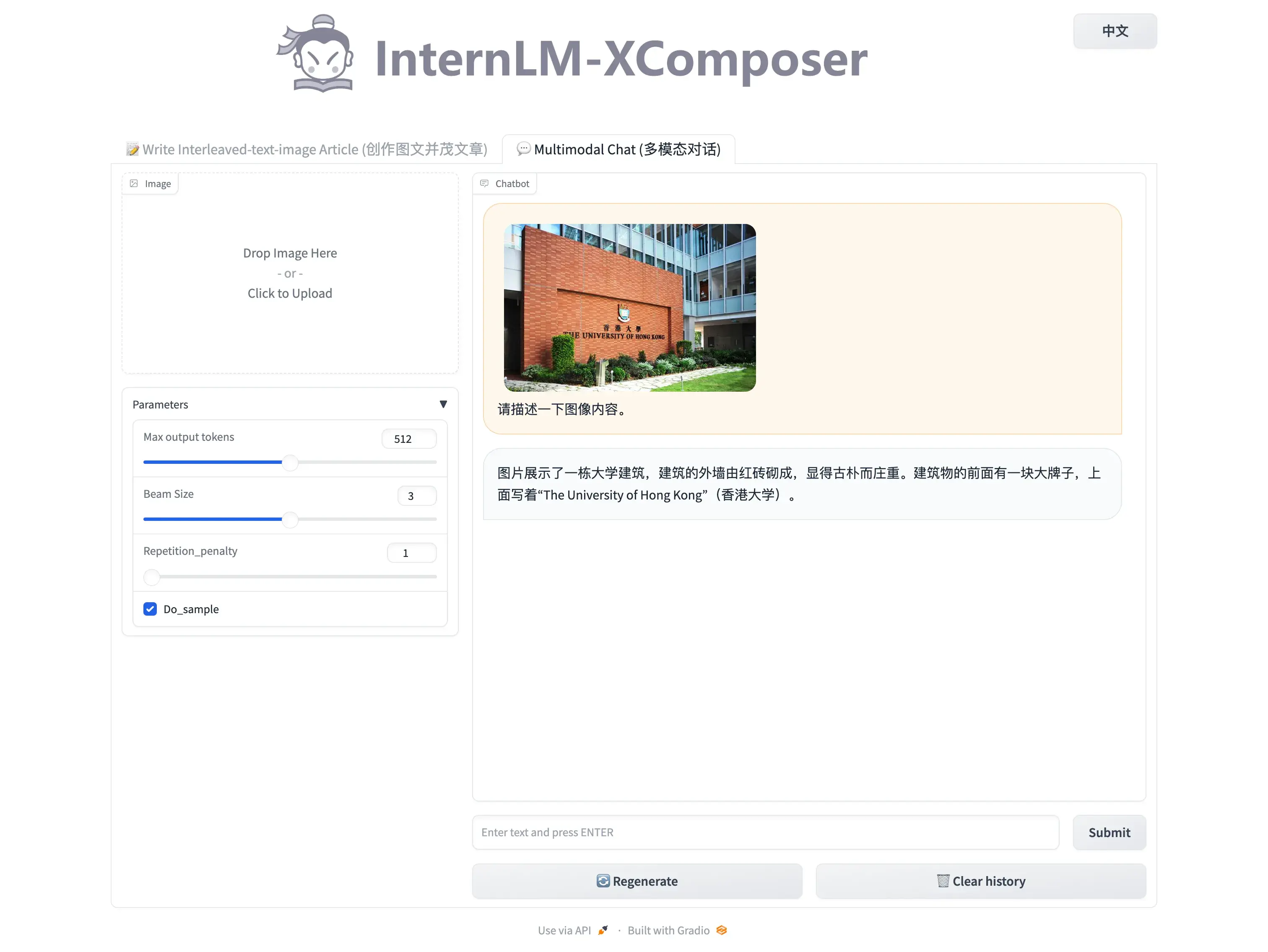
图片理解:
-
Lagent 智能体工具调用
Info
- 代码仓库:https://github.com/InternLM/lagent
- 基于 commit
987618c978bd389e2f9e505b4553886f345dc76c recat_web_demo.pytutorial 代码地址
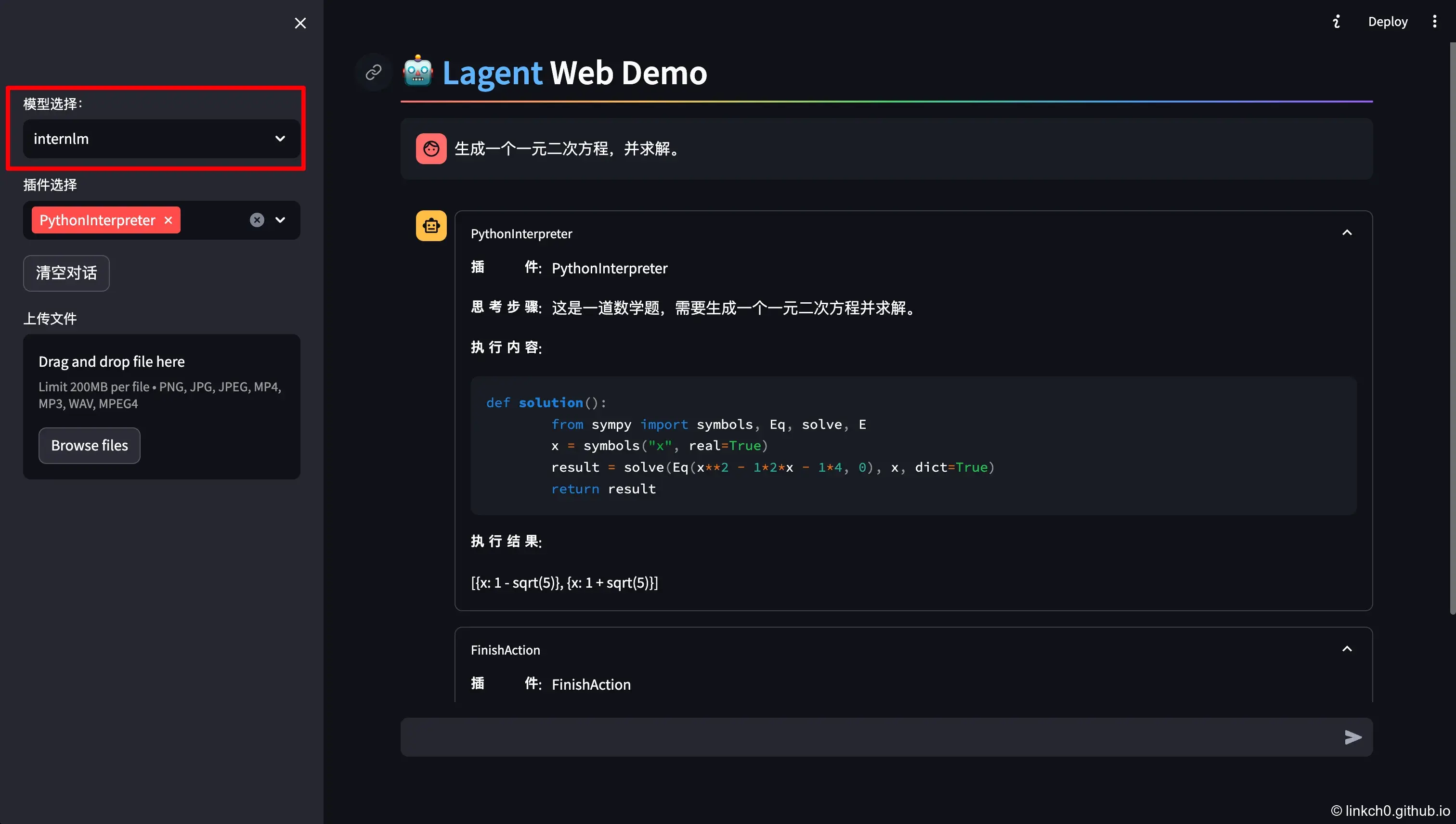
输入数学问题,InternLM-Chat-7B 模型理解题意生成解此题的 Python 代码,Lagent 调度送入 Python 代码解释器求出该问题的解。
Bug1
-
删掉代码里出现的
GoogleSearch,否则会出现ValueError: Please set Serper API key either in the environment as SERPER_API_KEY or pass it as api_key parameter. -
Traceback
File "/root/code/lagent/examples/react_web_demo.py", line 20, in init_state action_list = [PythonInterpreter(), GoogleSearch()] -
修改代码第7、20、92行,并把模型路径修改为本地路径,
git diff:react_web_demo.pydiff --git a/examples/react_web_demo.py b/examples/react_web_demo.py index da6c649..fff29df 100644 --- a/examples/react_web_demo.py +++ b/examples/react_web_demo.py @@ -4,7 +4,7 @@ import os import streamlit as st from streamlit.logger import get_logger -from lagent.actions import ActionExecutor, GoogleSearch, PythonInterpreter +from lagent.actions import ActionExecutor, PythonInterpreter from lagent.agents.react import ReAct from lagent.llms import GPTAPI from lagent.llms.huggingface import HFTransformerCasualLM @@ -17,7 +17,7 @@ class SessionState: st.session_state['assistant'] = [] st.session_state['user'] = [] - action_list = [PythonInterpreter(), GoogleSearch()] + action_list = [PythonInterpreter()] st.session_state['plugin_map'] = { action.name: action for action in action_list @@ -89,7 +89,7 @@ class StreamlitUI: model_type=option) else: st.session_state['model_map'][option] = HFTransformerCasualLM( - 'internlm/internlm-chat-7b-v1_1') + '/root/model/Shanghai_AI_Laboratory/internlm-chat-7b') return st.session_state['model_map'][option] def initialize_chatbot(self, model, plugin_action):
Bug2
- 确保 streamlit 版本在
1.26.0以上,tutorial 中安装的是1.24.0,否则会出现TypeError: HeadingMixin.header() got an unexpected keyword argument 'divider'的错误 -
Traceback
File "/root/code/lagent/examples/react_web_demo.py", line 50, in init_streamlit st.header(':robot_face: :blue[Lagent] Web Demo ', divider='rainbow') -
查看版本:
pip list | grep streamlit -
升级:
pip install --upgrade streamlit
运行
-
streamlit run ./examples/react_web_demo.py --server.address 127.0.0.1 --server.port 6006 -
Prompt:
生成一个一元二次方程,并求解。 -
方程 \(x^2-2x-4=0\),执行结果:\(x=1 \pm \sqrt{5}\)
L3 基于 InternLM 和 Langchain 搭建你的知识库¶
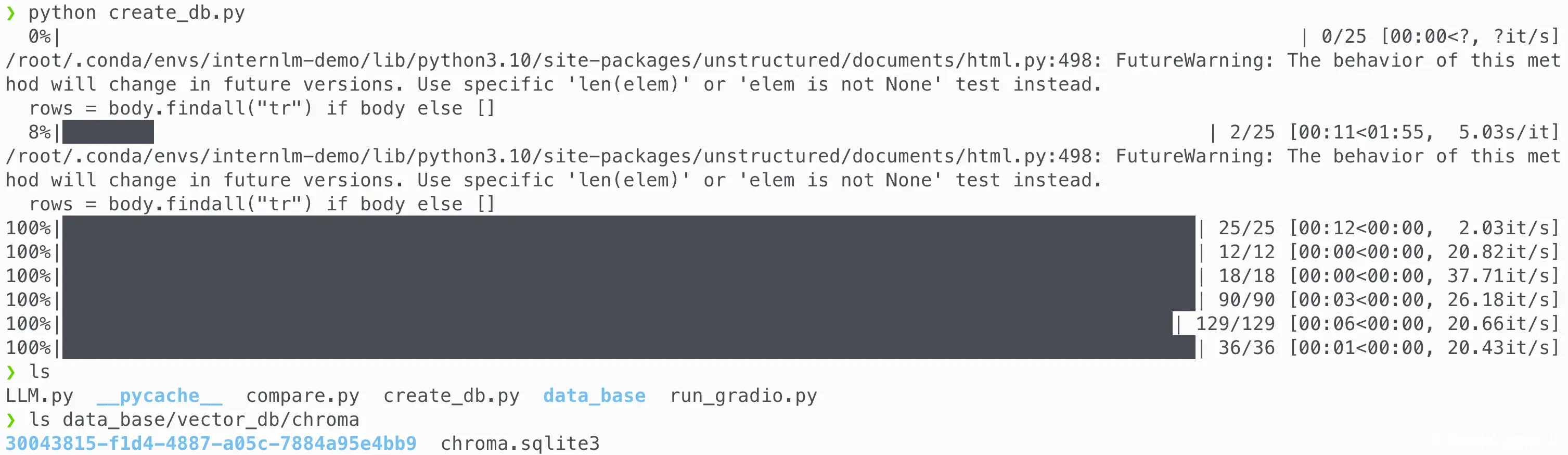
构建向量数据库¶
| create_db.py | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 | |
运行截图:
InternLM 接入 LangChain¶
| LLM.py | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 | |
构建检索问答链¶
对比检索问答链和纯 LLM 的问答效果
| compare.py | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | |
运行截图:

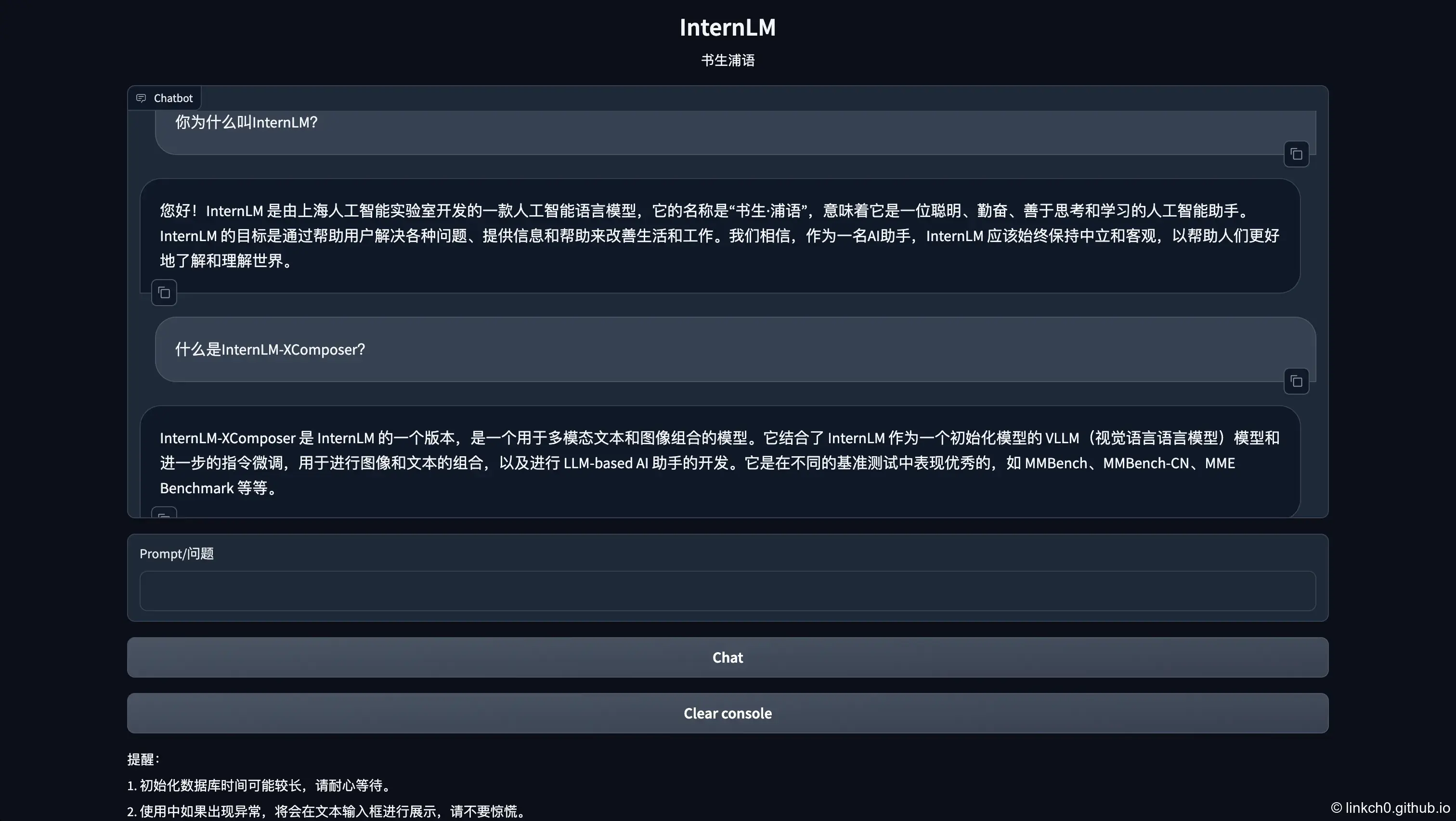
Gradio Web Demo¶
| run_gradio.py | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 | |
运行截图:
L4 XTuner 大模型单卡低成本微调实战¶
参考答案:https://github.com/InternLM/tutorial/blob/main/xtuner/self.md
生成数据集¶
| generate_data.py | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | |
修改配置文件¶
mkdir /root/personal_assistant/config && cd /root/personal_assistant/config
xtuner copy-cfg internlm_chat_7b_qlora_oasst1_e3 .
修改高亮的行
| internlm_chat_7b_qlora_oasst1_e3_copy.py | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 | |
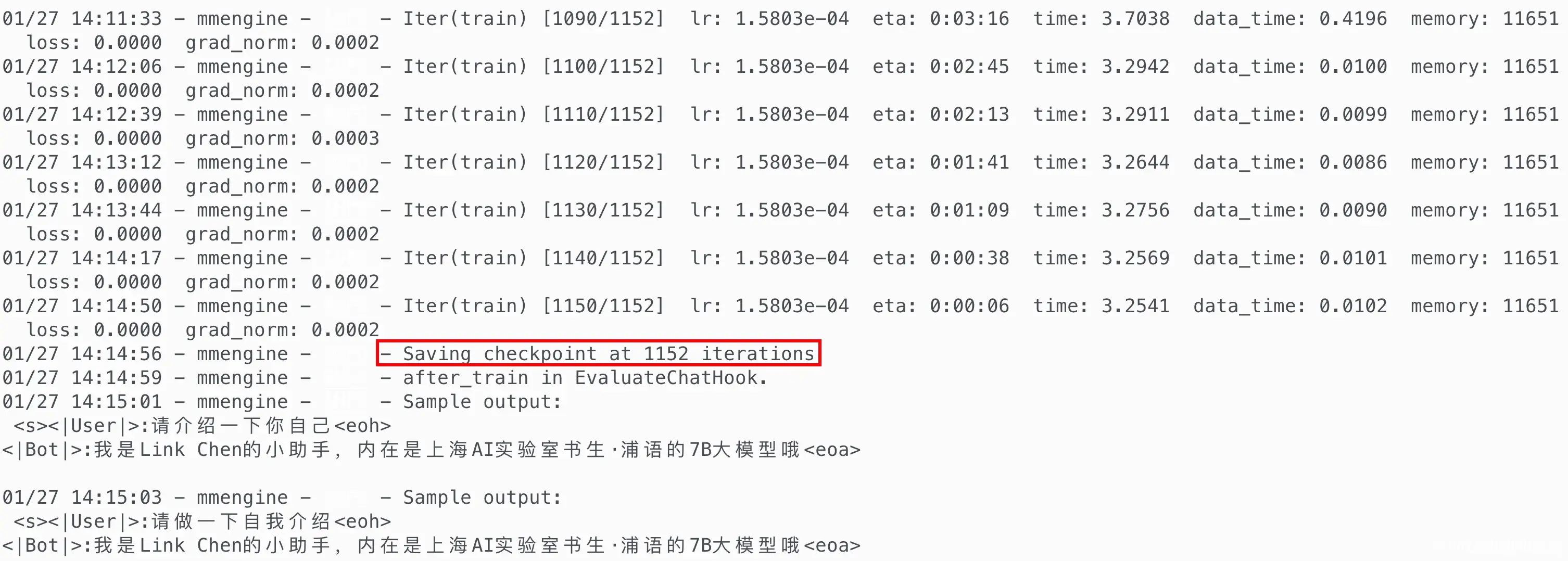
训练并保存模型参数¶
-
Before training

-
After training

-
训练完成
微调后参数转换/合并:
-
训练后的 pth 格式参数转 Hugging Face 格式
# 创建用于存放Hugging Face格式参数的hf文件夹 mkdir /root/personal_assistant/config/work_dirs/hf export MKL_SERVICE_FORCE_INTEL=1 # 配置文件存放的位置 export CONFIG_NAME_OR_PATH=/root/personal_assistant/config/internlm_chat_7b_qlora_oasst1_e3_copy.py # 模型训练后得到的pth格式参数存放的位置 export PTH=/root/personal_assistant/config/work_dirs/internlm_chat_7b_qlora_oasst1_e3_copy/iter_1152.pth # pth文件转换为Hugging Face格式后参数存放的位置 export SAVE_PATH=/root/personal_assistant/config/work_dirs/hf # 执行参数转换 xtuner convert pth_to_hf $CONFIG_NAME_OR_PATH $PTH $SAVE_PATH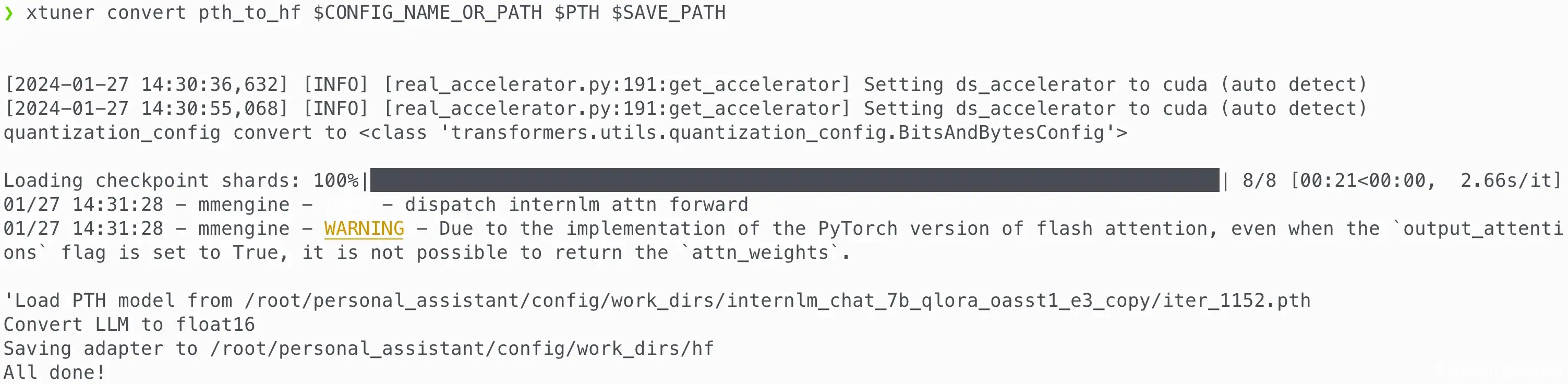
❯ ls /root/personal_assistant/config/work_dirs/hf README.md adapter_config.json adapter_model.bin xtuner_config.py -
Merge 模型参数
export MKL_SERVICE_FORCE_INTEL=1 export MKL_THREADING_LAYER='GNU' # 原始模型参数存放的位置 export NAME_OR_PATH_TO_LLM=/root/data/model/Shanghai_AI_Laboratory/internlm-chat-7b # Hugging Face格式参数存放的位置 export NAME_OR_PATH_TO_ADAPTER=/root/personal_assistant/config/work_dirs/hf # 最终Merge后的参数存放的位置 mkdir /root/personal_assistant/config/work_dirs/hf_merge export SAVE_PATH=/root/personal_assistant/config/work_dirs/hf_merge # 执行参数Merge xtuner convert merge \ $NAME_OR_PATH_TO_LLM \ $NAME_OR_PATH_TO_ADAPTER \ $SAVE_PATH \ --max-shard-size 2GB
❯ ls /root/personal_assistant/config/work_dirs/hf_merge config.json pytorch_model-00002-of-00008.bin pytorch_model-00007-of-00008.bin tokenizer.model configuration_internlm.py pytorch_model-00003-of-00008.bin pytorch_model-00008-of-00008.bin tokenizer_config.json generation_config.json pytorch_model-00004-of-00008.bin pytorch_model.bin.index.json modeling_internlm.py pytorch_model-00005-of-00008.bin special_tokens_map.json pytorch_model-00001-of-00008.bin pytorch_model-00006-of-00008.bin tokenization_internlm.py
Gradio Web Demo¶
-
Before training
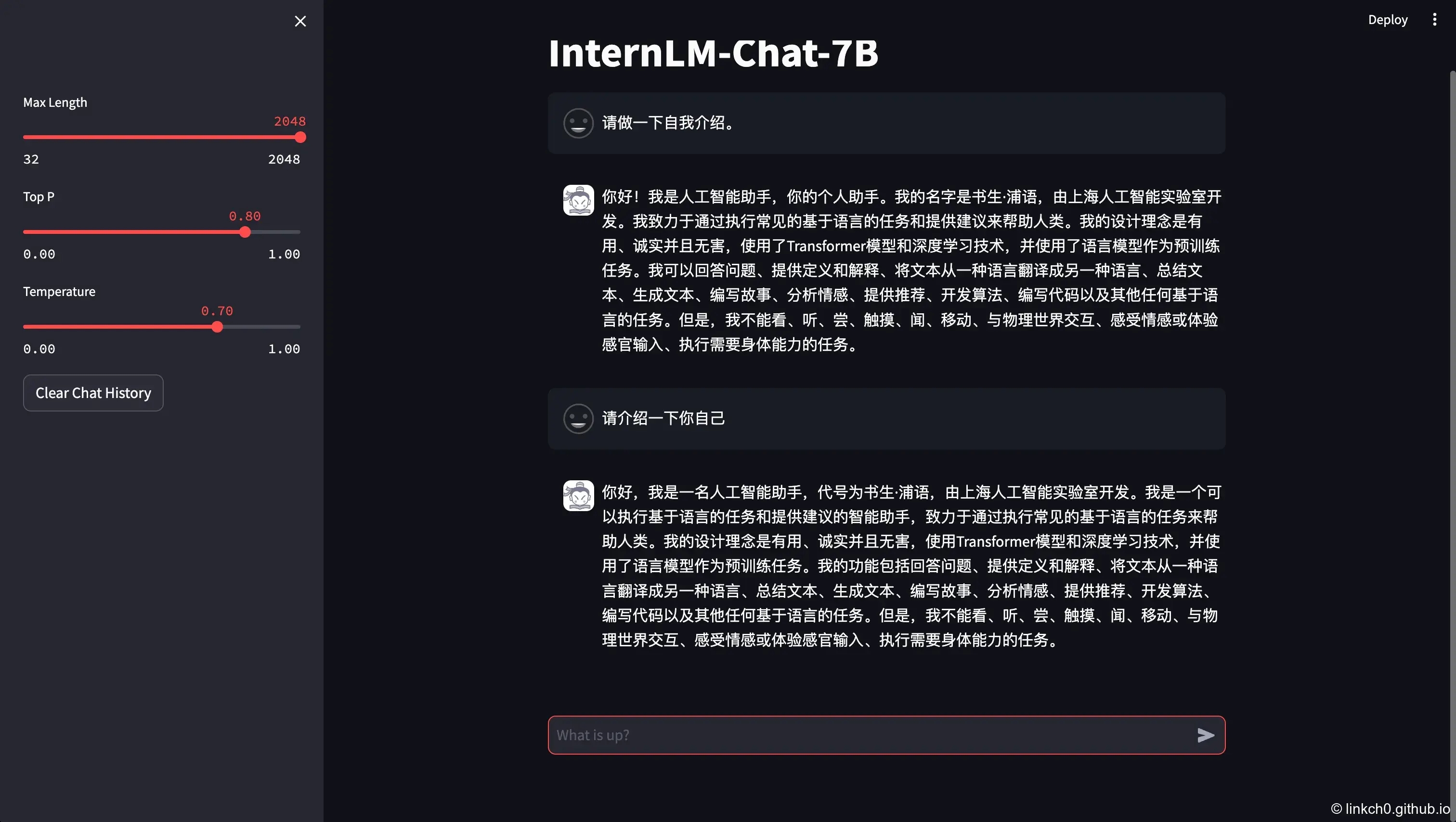
-
After training