Lectures¶
cd trace-viewer
npm run dev
Lecture 1 Overview, tokenization¶
http://localhost:5173/?trace=var/traces/lecture_01.json

- accuracy = efficiency x resources
- It's all about efficiency
- Efficiency drives design decisions
Basics¶
Goal: get a basic version of the full pipeline working
Components: tokenization, model architecture, training
Tokenization
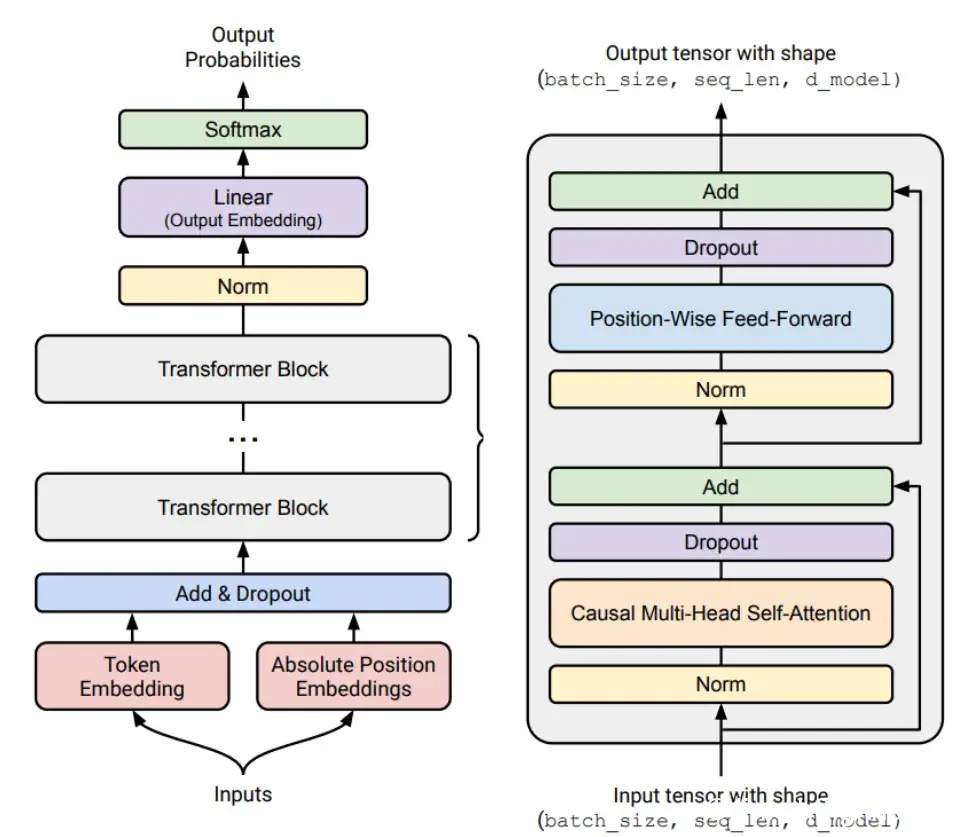
Architecture
Systems¶
Goal: squeeze the most out of the hardware
Components: kernels, parallelism, inference
Kernels
{kind=link}

Parallelism
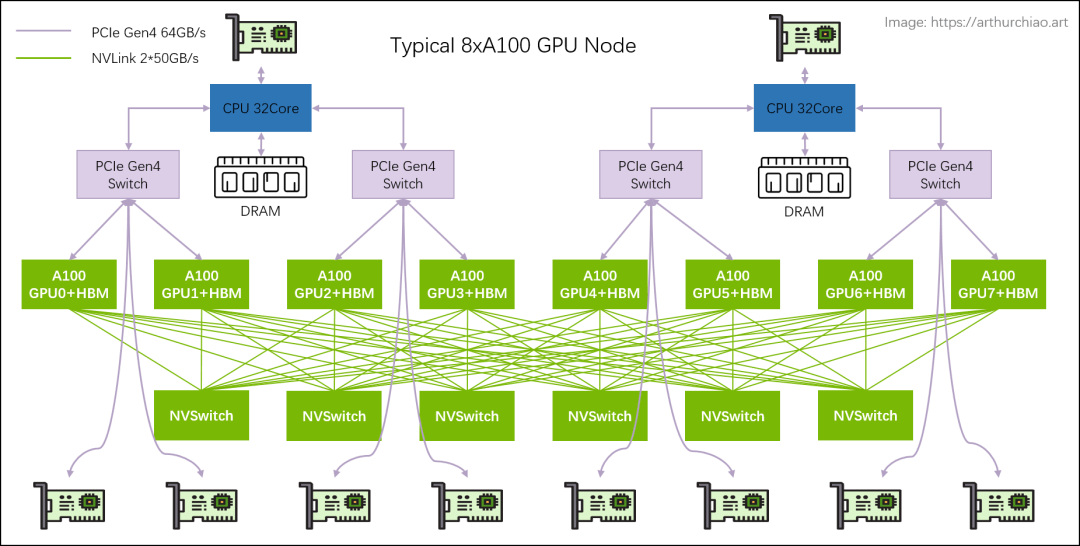{kind=link}
Inference
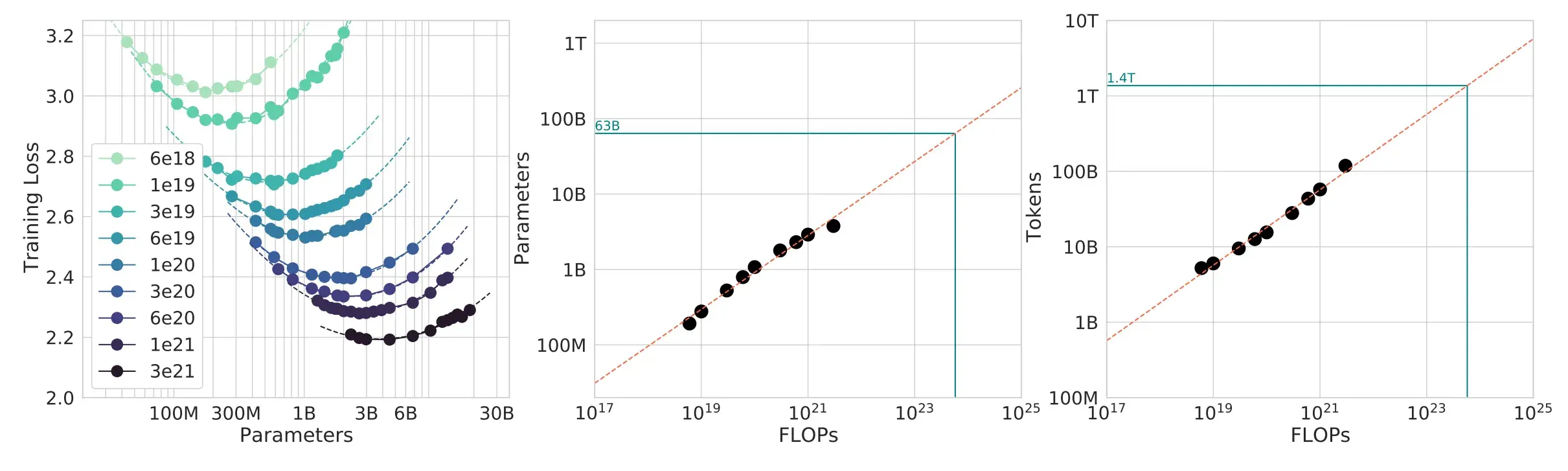
Scaling Laws¶
Goal: do experiments at small scale, predict hyperparameters/loss at large scale
Question: given a FLOPs budget (\(C\)), use a bigger model (\(N\)) or train on more tokens (\(D\))?
TL;DR: \(D^* = 20 N^*\) (e.g., 1.4B parameter model should be trained on 28B tokens)
Data¶
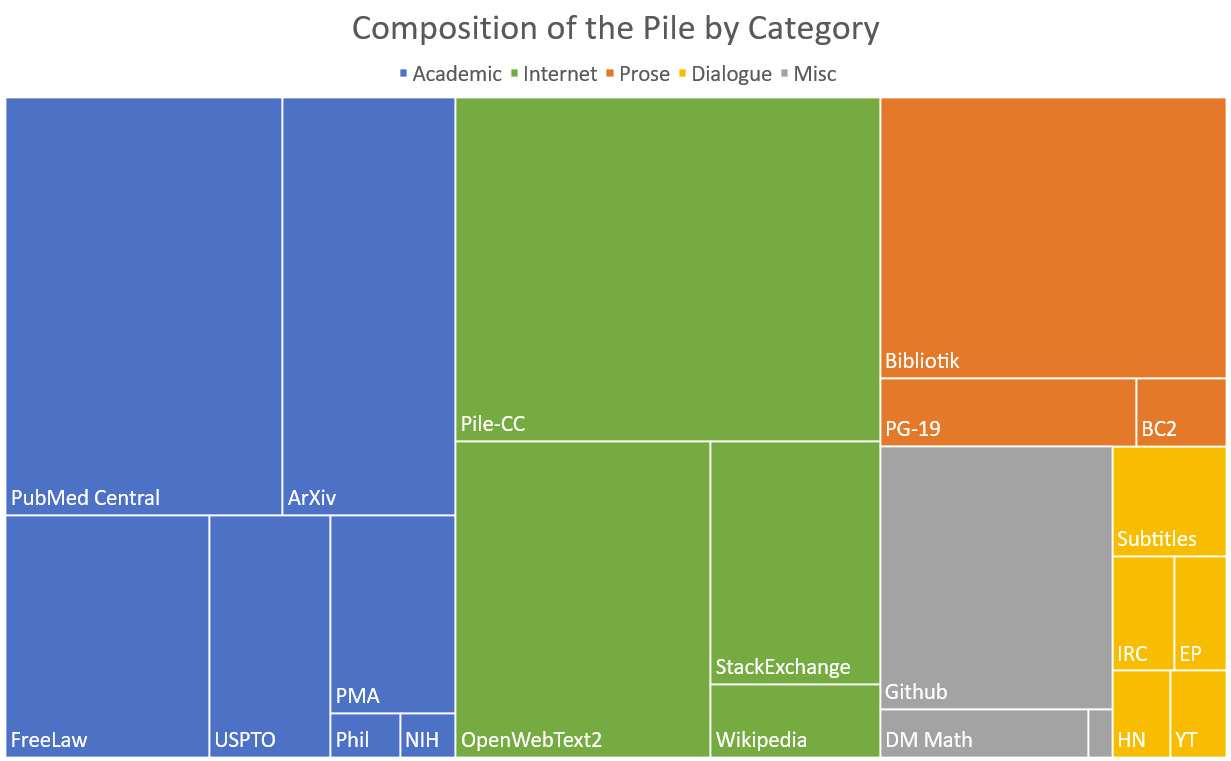{kind=link}
Evaluation
- Perplexity: textbook evaluation for language models
- Standardized testing (e.g., MMLU, HellaSwag, GSM8K)
- Instruction following (e.g., AlpacaEval, IFEval, WildBench)
Data curation
Data processing
Alignment¶
Supervised finetuning (SFT)
- Instruction data: (prompt, response) pairs
- Intuition: base model already has the skills, just need few examples to surface them. [Zhou+ 2023] (1000 examples)
- Supervised learning: fine-tune model to maximize p(response | prompt).
Preference data
- Data: generate multiple responses using model (e.g., [A, B]) to a given prompt.
- User provides preferences (e.g., A < B or A > B).
Verifiers
-
Formal verifiers (e.g., for code, math)
- Learned verifiers: train against an LM-as-a-judge
Algorithms
- Proximal Policy Optimization (PPO) from reinforcement learning [Schulman+ 2017][Ouyang+ 2022]
- Direct Policy Optimization (DPO): for preference data, simpler [Rafailov+ 2023]
- Group Relative Preference Optimization (GRPO): remove value function [Shao+ 2024]
Tokenization¶
Let's build the GPT Tokenizer Andrej Karpath

helloand\space hellois different token, space is a part of token-
The numbers are chopped from left to right.
-
Character-based tokenization
assert ord("a") == 97 assert ord("🌍") == 127757 assert chr(97) == "a" assert chr(127757) == "🌍"- Problem: Large and Sparse
- Problem 1: this is a very large vocabulary. There are approximately 150K Unicode characters. [Wikipedia]
- Problem 2: many characters are quite rare (e.g., 🌍), which is inefficient use of the vocabulary. Many sparsity.
-
Byte-based tokenization
assert bytes("a", encoding="utf-8") == b"a" assert bytes("🌍", encoding="utf-8") == b"\xf0\x9f\x8c\x8d"- Problem: Long sequences. Compression ratio is 1.
- Unicode strings can be represented as a sequence of bytes, which can be represented by integers between 0 and 255. The most common Unicode encoding is UTF-8
- The compression ratio is terrible, which means the sequences will be too long.
-
Word-based tokenization
GPT2_TOKENIZER_REGEX = \ r"""'(?:[sdmt]|ll|ve|re)| ?\p{L}+| ?\p{N}+| ?[^\s\p{L}\p{N}]+|\s+(?!\S)|\s+"""- Problem: Unfixed vocabulary size. UNK token.
- Use regular expression to split strings into words
- New words we haven't seen during training get a special UNK token, which is ugly and can mess up perplexity calculations.
-
Byte Pair Encoding (BPE)
- Basic idea: train the tokenizer on raw text to automatically determine the vocabulary
- Intuition: common sequences of characters are represented by a single token, rare sequences are represented by many tokens.
- Sketch: start with each byte as a token, and successively merge the most common pair of adjacent tokens.


Lecture 2 PyTorch, resource accounting¶
http://localhost:5173/?trace=var/traces/lecture_02.json